Automating and Standardizing Care Gaps from Payers to Providers
Authors: Chenghao Guo, Ashish Gupta
In the complex world of healthcare data management, standardization is key to efficient operations and improved patient care. We’re excited to share a project that addresses a common challenge in the industry: the inconsistent formats and naming conventions of patient care gap files from various payers. Our open-source Python-based ETL (Extract, Transform, Load) solution aims to standardize these files into a uniform, easily consumable format.
What Are Care Gaps and Why Is Standardization Important?
Care gaps refer to the discrepancies between recommended best practices in healthcare and the actual care received by patients. These gaps can include missed preventive screenings, overdue follow-ups, or unaddressed chronic condition management needs. Identifying and addressing care gaps is crucial for:
- Improving patient outcomes
- Reducing healthcare costs
- Enhancing quality measures and performance metrics
Payers (insurance companies) often provide care gap reports to healthcare providers, highlighting areas where patients may need additional attention. However, these reports come in various formats, making it challenging for providers to process and act on this information efficiently.
Unifying, standardizing, and processing care gap data in near real-time is essential because:
- It gives providers a comprehensive view of patient needs across all payers.
- It enables quicker identification and addressing of critical care needs.
- It facilitates better resource allocation and care coordination.
- It supports data-driven decision-making and quality improvement initiatives.
Automating the standardization process can significantly reduce the time and effort required to turn raw payer data into actionable insights, ultimately leading to better patient care.
Our Approach: A Flexible, Modular ETL System
Healthcare providers often receive care gap files from multiple payers, each with its own format, column names, and data structures. This inconsistency creates significant overhead in data processing and analysis, potentially impacting the quality and timeliness of patient care.
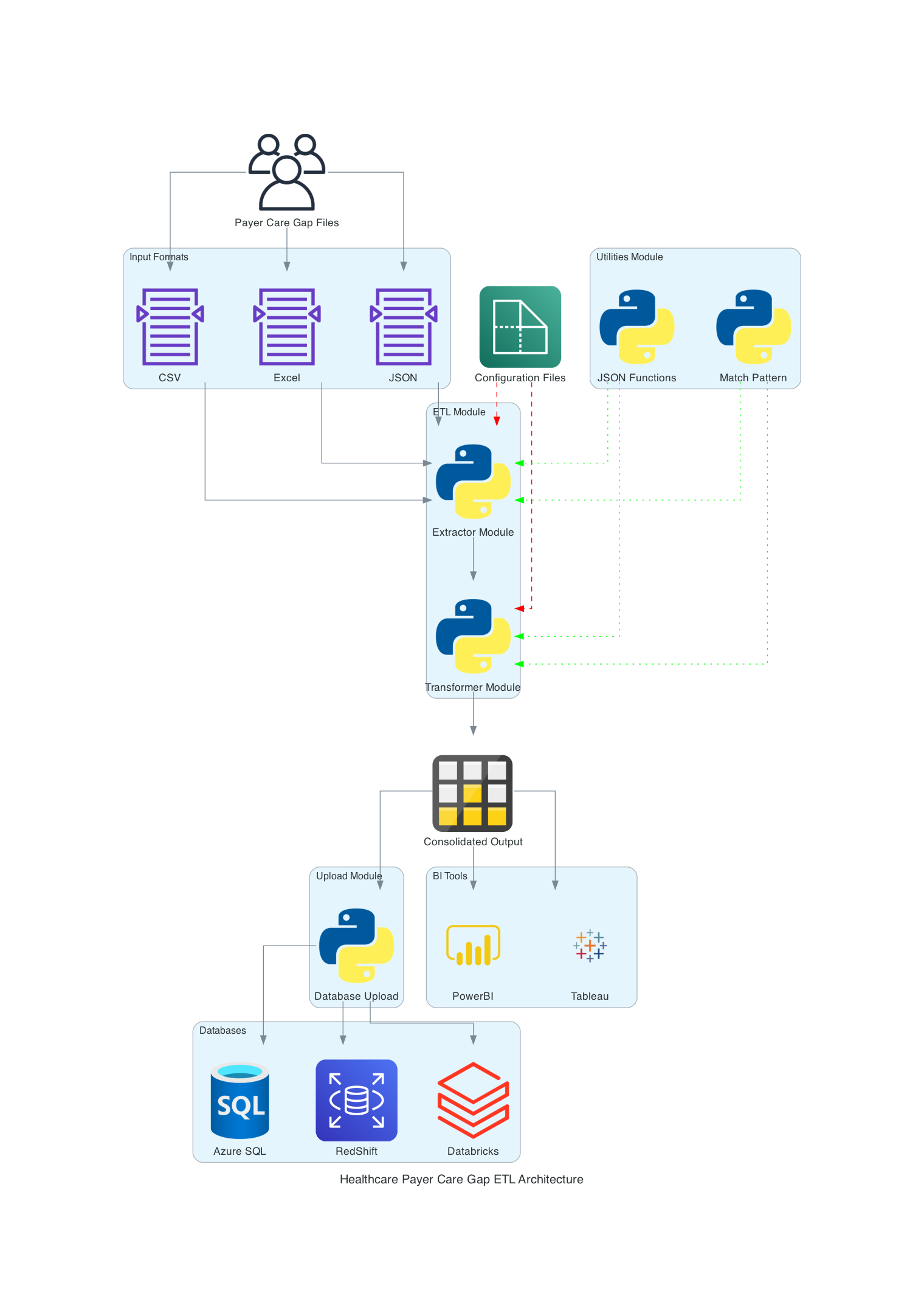
We've developed a flexible, modular Python-based ETL system that can handle various input formats and standardize them into a consistent output. Here are the key features of our solution:
- Modular Architecture: The project is divided into three main components:
- ETL Modules: Handle the core Extract, Transform, and Load processes
- Utility Modules: Provide common functions used across the project
- Upload Modules: Manage data upload to various database systems
- Configuration-Driven Approach: Extensive use of JSON configuration files allows easy adaptation to different data sources and targets without changing the core code.
- Database Agnostic: The system is designed to work with various database systems, including SQL Server, RedShift, Databricks, etc.
Sample Payer Files
To illustrate the challenge, let's look at sample care gap files from two different payers. Note that these are mock data with all PHI (Protected Health Information) removed.
Payer 1:
Payer1 provides an Excel file in a pivot table format, where each row represents one patient and columns represent different measures:
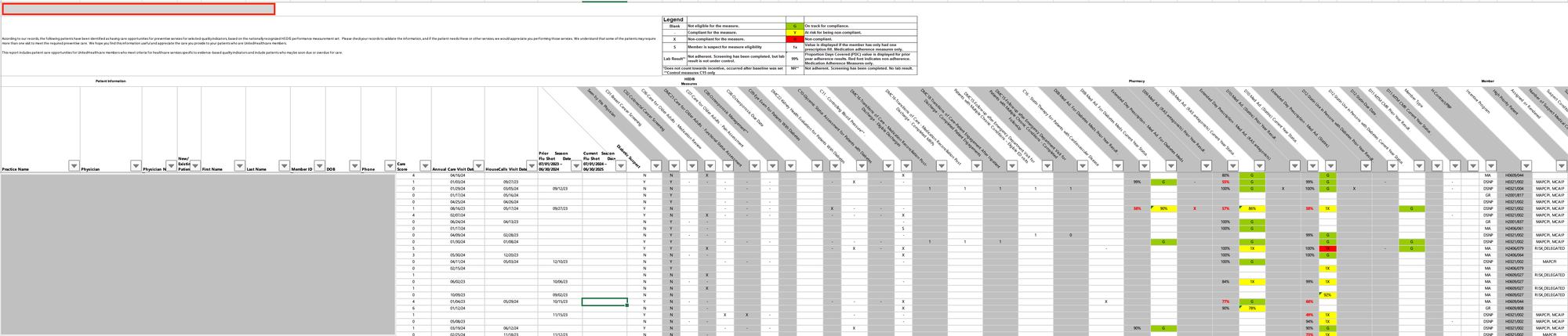
In this format:
- Each row corresponds to a single patient
- Each measure has its own column
- The status of each measure is directly in the cell
Payer 2:
Payer2 sends an Excel file in a "long" or "normalized" format, where each row represents a single measure for a patient:
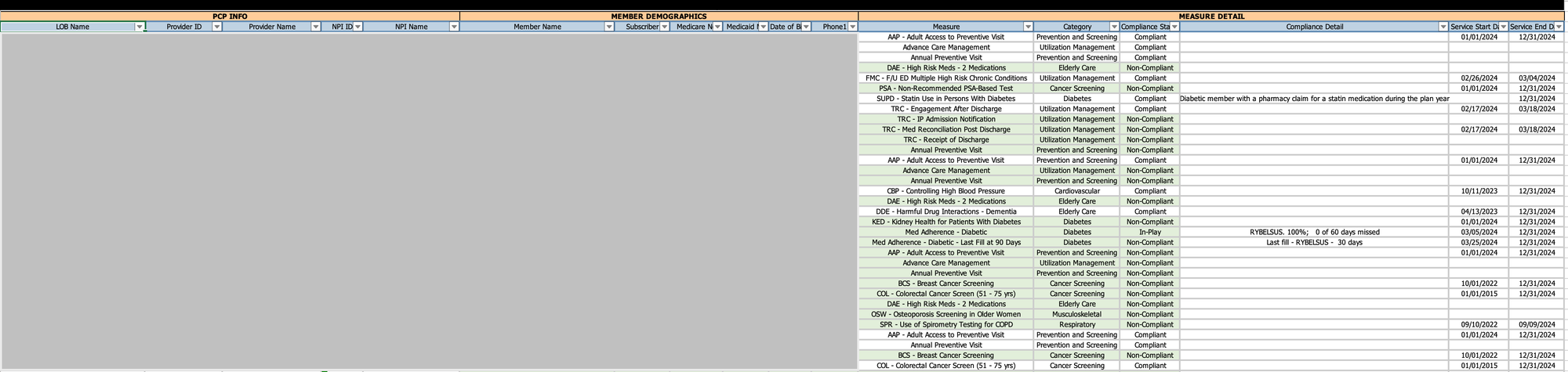
In this format:
- Each row represents a single measure for a patient
- A patient may have multiple rows, one for each applicable measure
- Measure names and statuses are in separate columns
As you can see, these files have different column names, date formats, and ways of representing similar information. This inconsistency makes it challenging for healthcare providers to efficiently process and act on care gap data from multiple payers.
Desired Outcome and Its Advantages
Our goal is to transform the varied inputs from different payers into a standardized, normalized format that can be easily consumed by healthcare providers' systems. The output format we've designed includes a comprehensive set of fields that capture all necessary information about care gaps, patient details, and provider information.
Our standardized output includes the following columns:
- Patient_ID: Unique identifier for the patient
- Patient_Name: Full name of the patient
- Gender: Patient's gender
- DOB: Date of birth
- Age: Calculated age of the patient
- Insurance_Carrier: Name of the insurance company
- LOB: Line of Business (e.g., Medicare Advantage, Commercial)
- PCP: Primary Care Provider name
- PCP_NPI: National Provider Identifier for the PCP
- Provider_Group: Name of the provider group or practice
- Provider_Group_TIN: Tax Identification Number for the provider group
- Measure_ID: Unique identifier for the quality measure
- Measure_ABBR: Abbreviated name of the measure
- Measure: Full name of the quality measure
- Measure_Status: Current status of the measure (e.g., Open, Closed)
- Numerator: 1 represents the patient meet the criteria of the measure
- Denominator: 1 represents the patient is eligible for this measure
- Measure_Year: The year for which the measure is applicable
- Measure_Start_Date: Start date of the measurement period
- Measure_Due_Date: Due date for closing the care gap
- Contract: Specific contract or plan under the insurance carrier
- Source_Month: Month of the data source
- Source: Original source file or system of the data
This comprehensive set of fields ensures we capture all relevant information from various payer sources, allowing for detailed analysis and actionable insights.
This standardized, normalized format offers numerous advantages:
- Consistent Data Structure: All data is transformed into a uniform format, regardless of the source payer, simplifying downstream processing and analysis.
- Standardized Field Names: All columns have consistent names, making it easier to process and analyze the data across different payers.
- Standardized Measure Names and Status: Care gap measures and their statuses are named consistently across all payers, facilitating easier aggregation and comparison.
- Simplified Data Model: The one-patient-one-measure-per-row format aligns well with relational database principles, optimizing storage, querying, and analysis.
- Scalability: This format easily accommodates new measures or payers without requiring changes to the data structure.
- Efficient Querying and Analysis: It's straightforward to filter, aggregate, and analyze data based on any combination of patient, measure, status, or payer.
- Easier Data Integration: The consistent format facilitates integration with other healthcare data systems, analytics tools, and reporting platforms.
- Flexibility in Analysis: Users can easily pivot or reshape the data as needed for different types of analysis, reporting, or visualization.
- Optimized for Time-Series Analysis: The format makes it simple to track changes in measure status over time for individual patients or populations.
This standardized output can be used for various critical healthcare management functions:
- Population Health Management: Easily identify patients with open care gaps across all payers.
- Quality Improvement Initiatives: Track closure rates of specific measures over time.
- Patient Outreach: Generate lists of patients needing specific screenings or interventions.
- Performance Reporting: Aggregate data for internal quality metrics or external reporting requirements.
- Care Coordination: Provide care managers with a comprehensive view of patient needs across all payers.
Challenges Faced and Solutions Implemented
Developing a flexible ETL system for healthcare data presents numerous challenges. Here are some of the key obstacles we encountered and the solutions we implemented:
1. Diverse File Formats and Structures
Challenge: Different payers provide data in various formats (CSV, Excel, JSON) and structures (wide vs. long format), making it challenging to create a unified processing pipeline.
Solutions:
- Our Approach: We developed a flexible, configuration-driven system that adapts to different file types and structures without changing the core code.
- Code Details: The
PayorDataExtractorclass uses these configurations to dynamically adjust its extraction method based on the input file.
2. Inconsistent Column Naming and Data Values
Challenge: Column names and data values often vary between payers, making it challenging to standardize the data.
Solutions:
- Our Approach: Created a robust mapping system to standardize column names and data values across different sources.
- To address inconsistent column naming and data values, we created methods in the
PayorDataTransformerclass to map columns and values using configuration files.
3. Complex Measure Calculations
Challenge: Some healthcare measures require complex calculations based on multiple data points.
Solutions:
- Our Approach: Developed a centralized system for measuring computations, ensuring consistency and maintainability.
- Code Details: We implemented a dedicated
_calculate_measuremethod in thePayorDataTransformerclass. This method contains logic for various measure calculations.
4. Maintaining Data Quality and Integrity
Challenge: Ensuring data quality and integrity throughout the ETL process is crucial in healthcare analytics.
Solutions:
- Our Approach: Implemented comprehensive data validation and cleaning steps throughout the process.
- Code Details: We implemented various data cleaning and validation steps in the
_clean_datamethod of thePayorDataTransformerclass. This includes handling missing values, removing duplicates, and validating data types.
5. Adapting to Changing Payer Requirements
Challenge: Payer reporting requirements and file formats can change over time, requiring frequent updates to the ETL process.
Solutions:
- Our Approach: Designed a system that can quickly adapt to changes without major code modifications.
- Code Details: By updating the JSON configuration files
payor_files_config.json, we can adjust to new file formats, column names, or data values without modifying the core Python code. This significantly reduces the time and risk involved in adapting to payer changes.
6. Database Agnosticism
Challenge: Different healthcare organizations may use different database systems, making it difficult to create a one-size-fits-all solution.
Solutions:
- Our Approach: Designed the system to be compatible with various database systems.
- Code Details: We designed our system to be database-agnostic by creating separate database connection classes (like
AzureSQLDatabaseConnection) that encapsulate database-specific operations. This modular approach allows easy integration with different database systems by creating new connection classes as needed.
7. Ensuring Scalability
Challenge: As the number of payers and data volume grows, ensuring the system can scale becomes crucial.
Solutions:
- Our Approach: Designed the ETL process to be modular and parallel-processing friendly.
- Code Details: We designed our ETL process to be modular and parallel-processing friendly. The main ETL script (
main_payor_file.py) can be easily modified to process multiple files concurrently using multiprocessing, significantly improving performance for large datasets.
By addressing these challenges, we've created a robust, flexible, and scalable ETL system capable of handling the complex and diverse nature of healthcare data from multiple payers. This system not only streamlines our current data processing needs but is also well-positioned to adapt to future changes in the healthcare data landscape.
Technical Deep Dive
Let's explore the technical aspects of our ETL solution, focusing on its modular architecture, configuration-driven approach, and database-agnostic design.
Modular Architecture
Our project is divided into three main components:
1. ETL Modules
These modules handle the core Extract, Transform, and Load processes. Key classes include:
The ETL modules form the core of our data processing pipeline, handling healthcare data extraction, transformation, and loading.
a. PayorDataExtractor (extractor.py)
The PayorDataExtractor class reads data from various file types and converts them into pandas’ DataFrames.
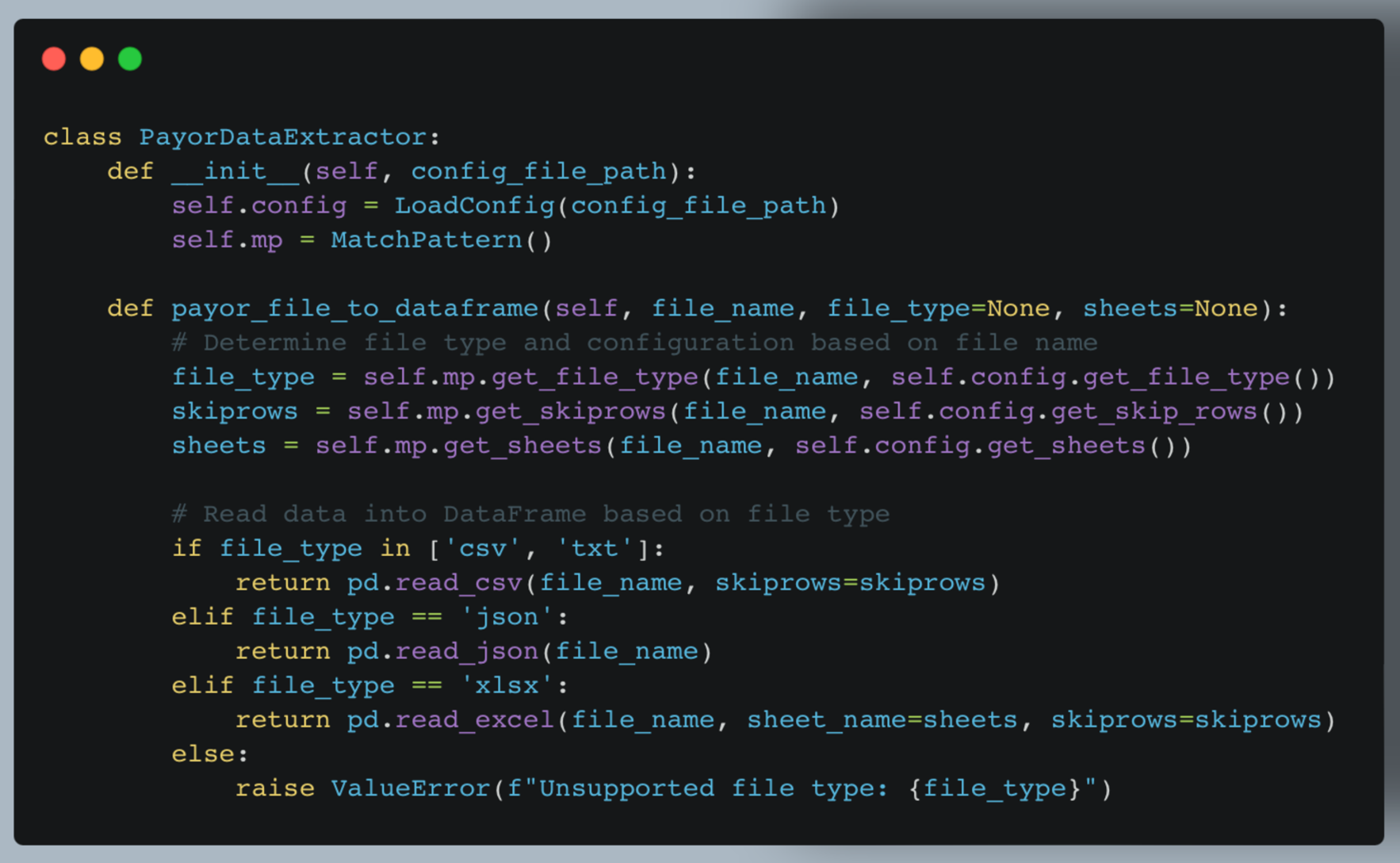
Key features:
- Supports multiple file types (CSV, JSON, Excel)
- Uses configuration to determine file-specific settings
- Handles multi-sheet Excel files
b. PayorDataTransformer (transformer.py)
The PayorDataTransformer class standardizes the extracted data, applying various transformations based on the configuration.
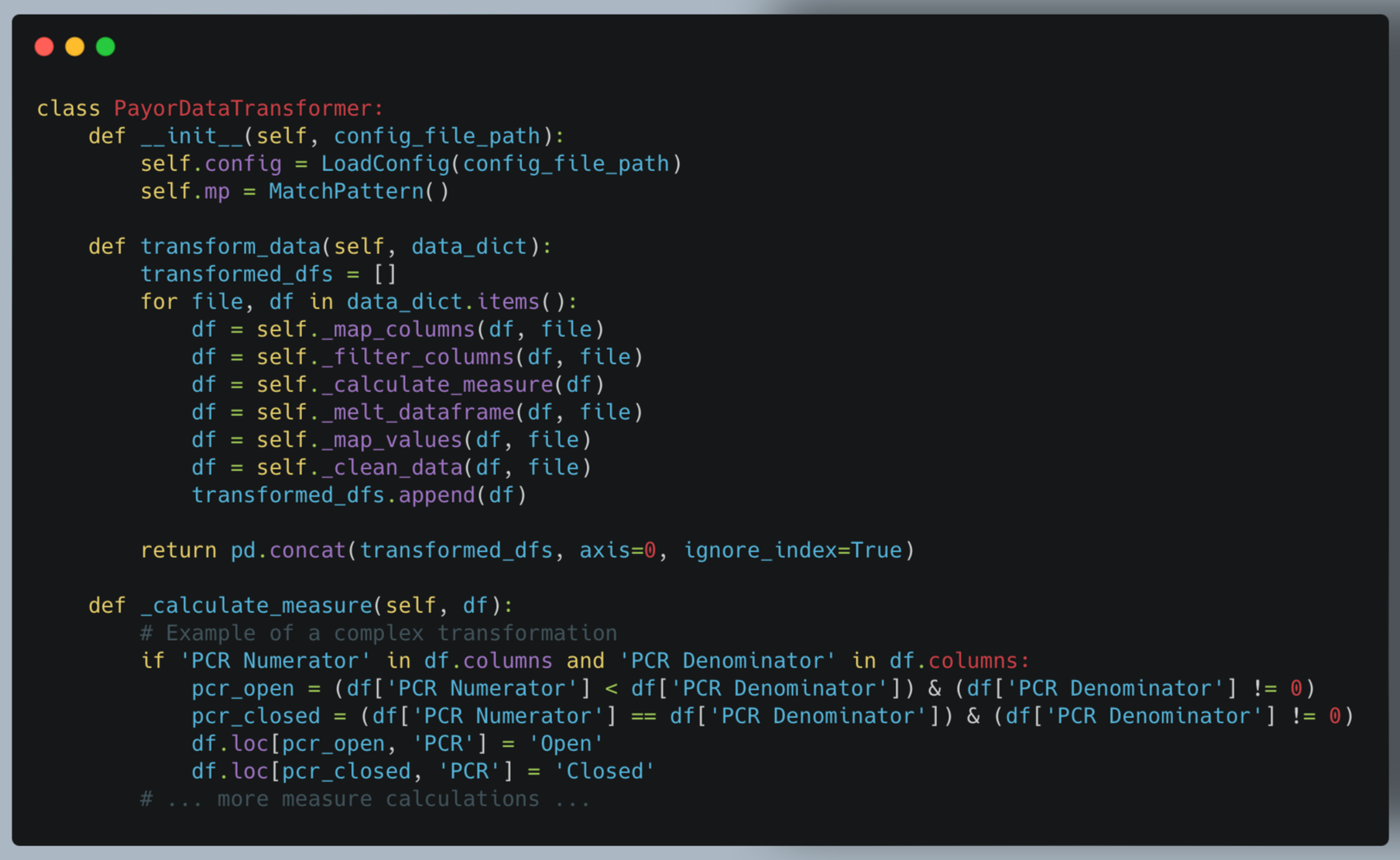
Key features:
- Applies multiple transformation steps (mapping, filtering, calculating measures etc)
- Handles complex logic for measure calculations
- Standardizes data across different source formats
c. Main ETL Process (main_payor_file.py)
This script orchestrates the entire ETL process, combining extraction, transformation, and loading.
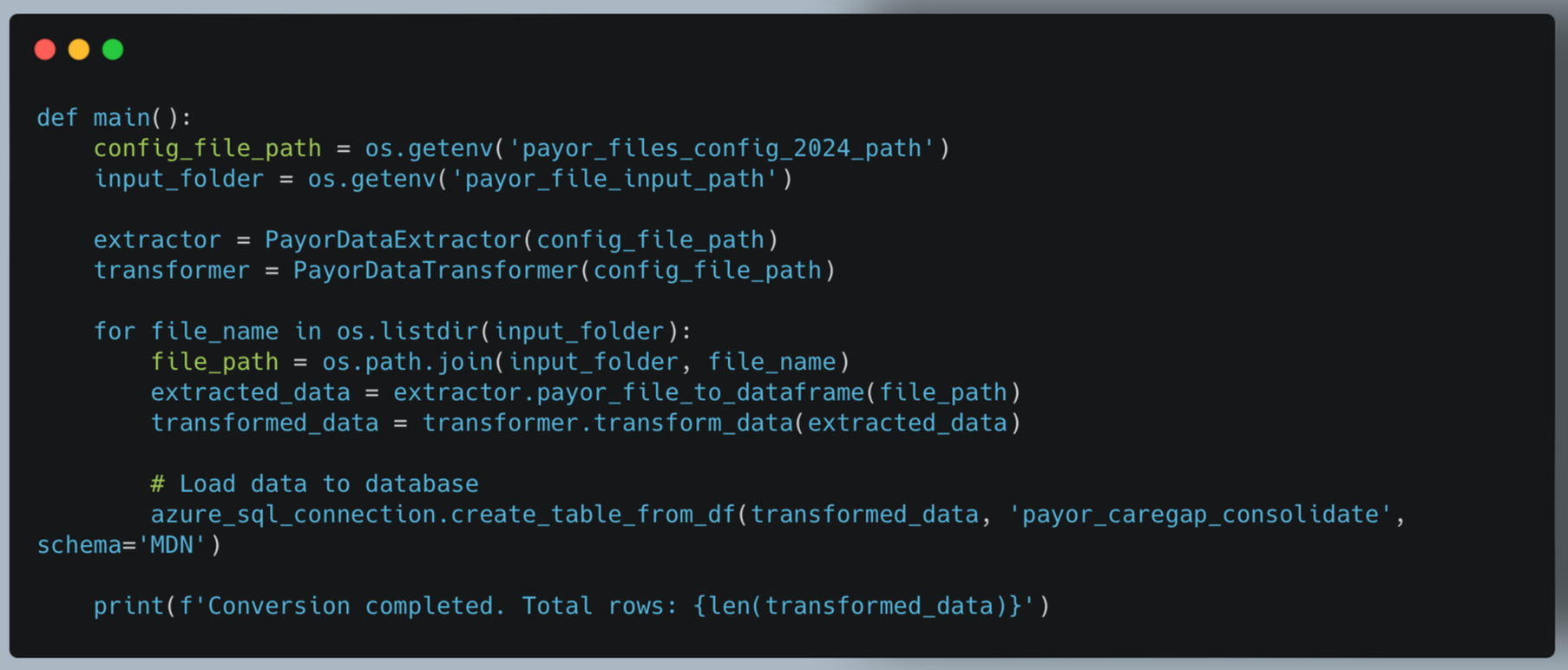
Key features:
- Iterates through input files
- Coordinates extraction and transformation
- Handles database loading
- Provides process summary
2. Utility Modules
These modules provide essential supporting functions used throughout the ETL process.
a. LoadConfig (json_functions.py)
The LoadConfig class manages the loading and parsing of JSON configuration files.
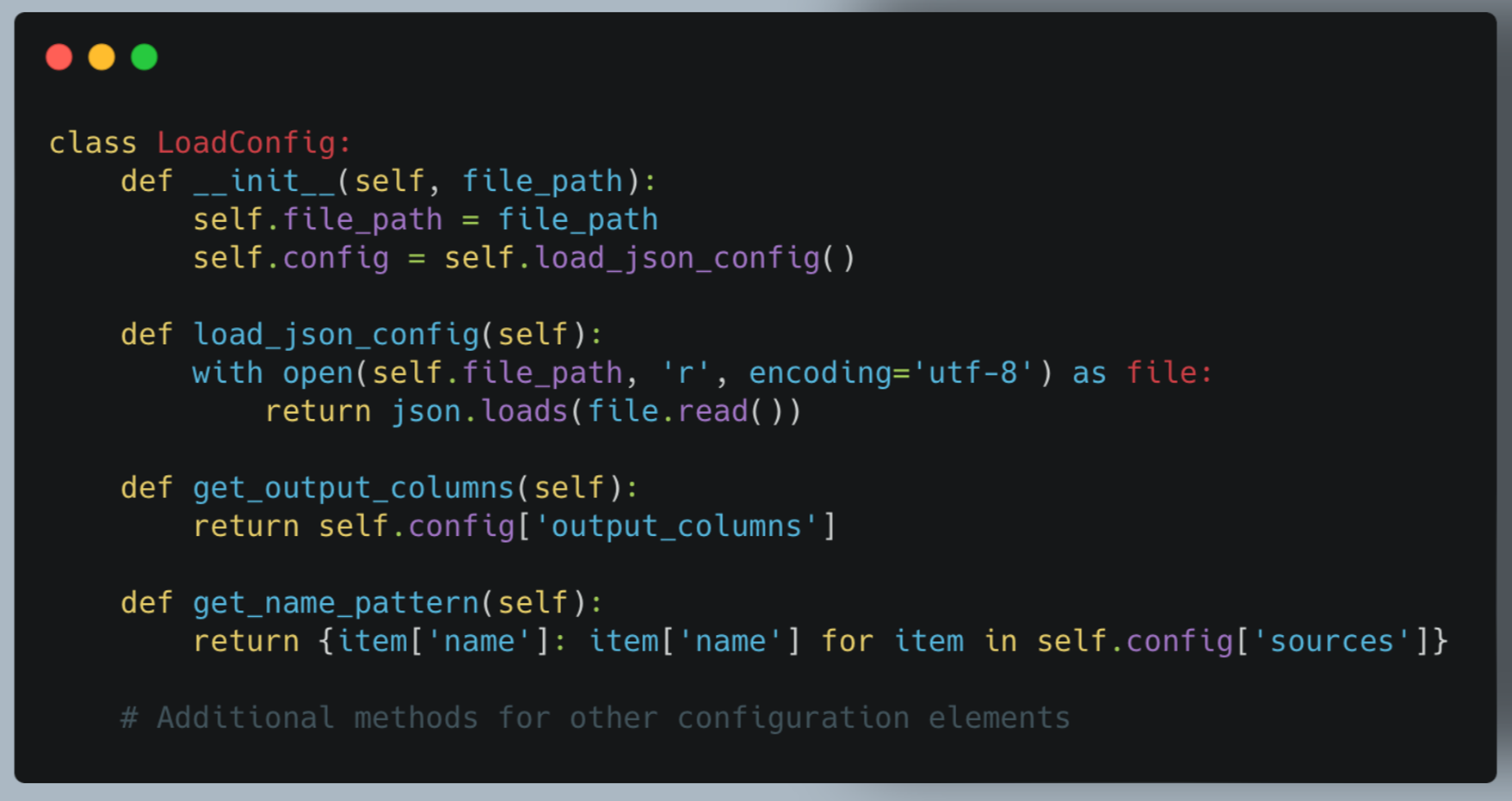
Key features:
- Centralizes configuration management
- Provides easy access to different configuration sections
- Handles potential JSON parsing errors
b. MatchPattern (match_pattern.py)
The MatchPattern class provides flexible pattern matching for file names and configurations.
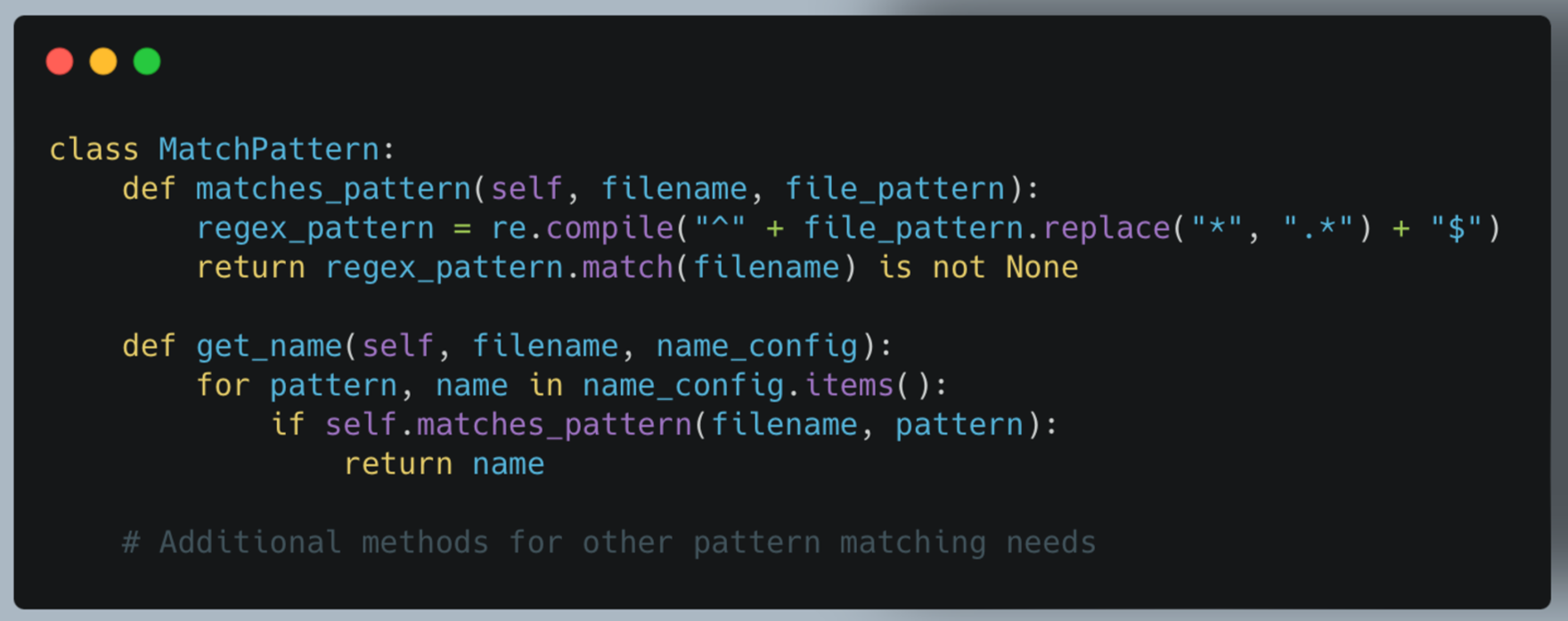
Key features:
- Uses regex for flexible pattern matching
- Supports wildcard (*) in patterns
- Provides methods for various configuration lookups based on file names
3. Upload Modules
These modules handle the interaction with different data storage systems. We use Azure as example.
a. AzureBlobDownloader (azure_blob_download.py)
This class manages downloading files from Azure Blob storage.
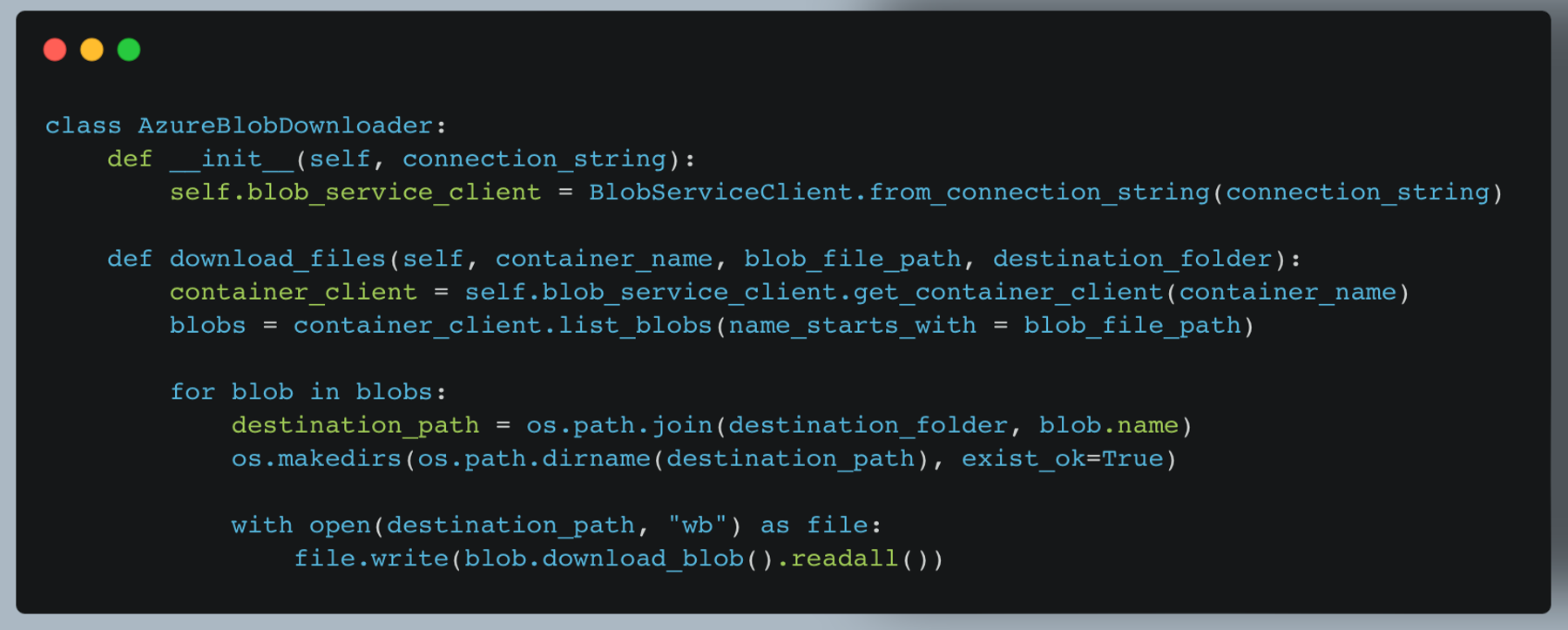
Key features:
- Connects to Azure Blob storage
- Downloads multiple files based on the path prefix
- Maintains folder structure in the destination
b. AzureSQLDatabaseConnection (azure_sql_connection.py)
This class manages the connection and data upload to the Azure SQL Database.
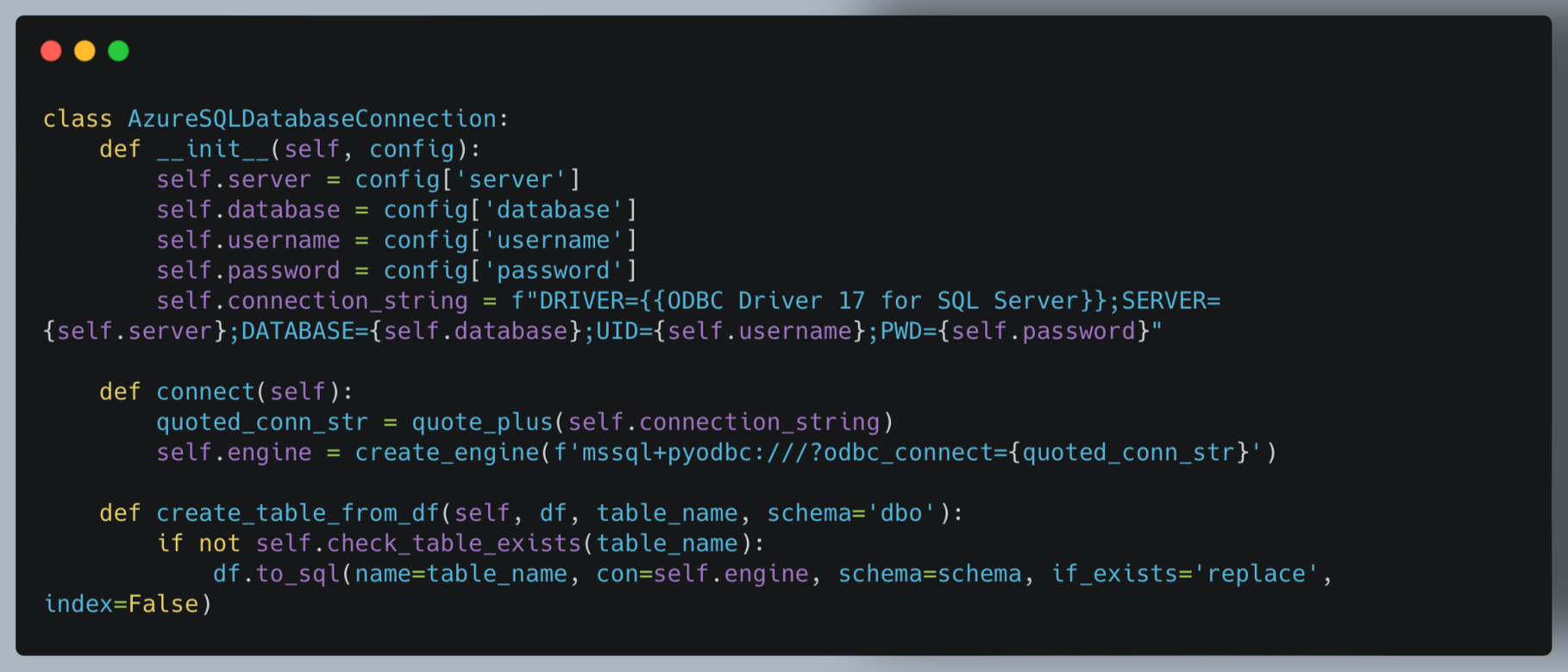
Key features:
- Manages database connection using SQLAlchemy
- Supports creating or replacing tables from DataFrames
- Includes utility methods for checking table existence and appending data
By leveraging these modular components and a configuration-driven approach, our ETL solution provides a flexible, maintainable, and extensible system for standardizing healthcare data across various payers and formats.
4. Configuration File Structure
The heart of our system's flexibility lies in its configuration-driven approach. The payor_files_config.json file defines how different source files should be processed. Let's break down its structure:
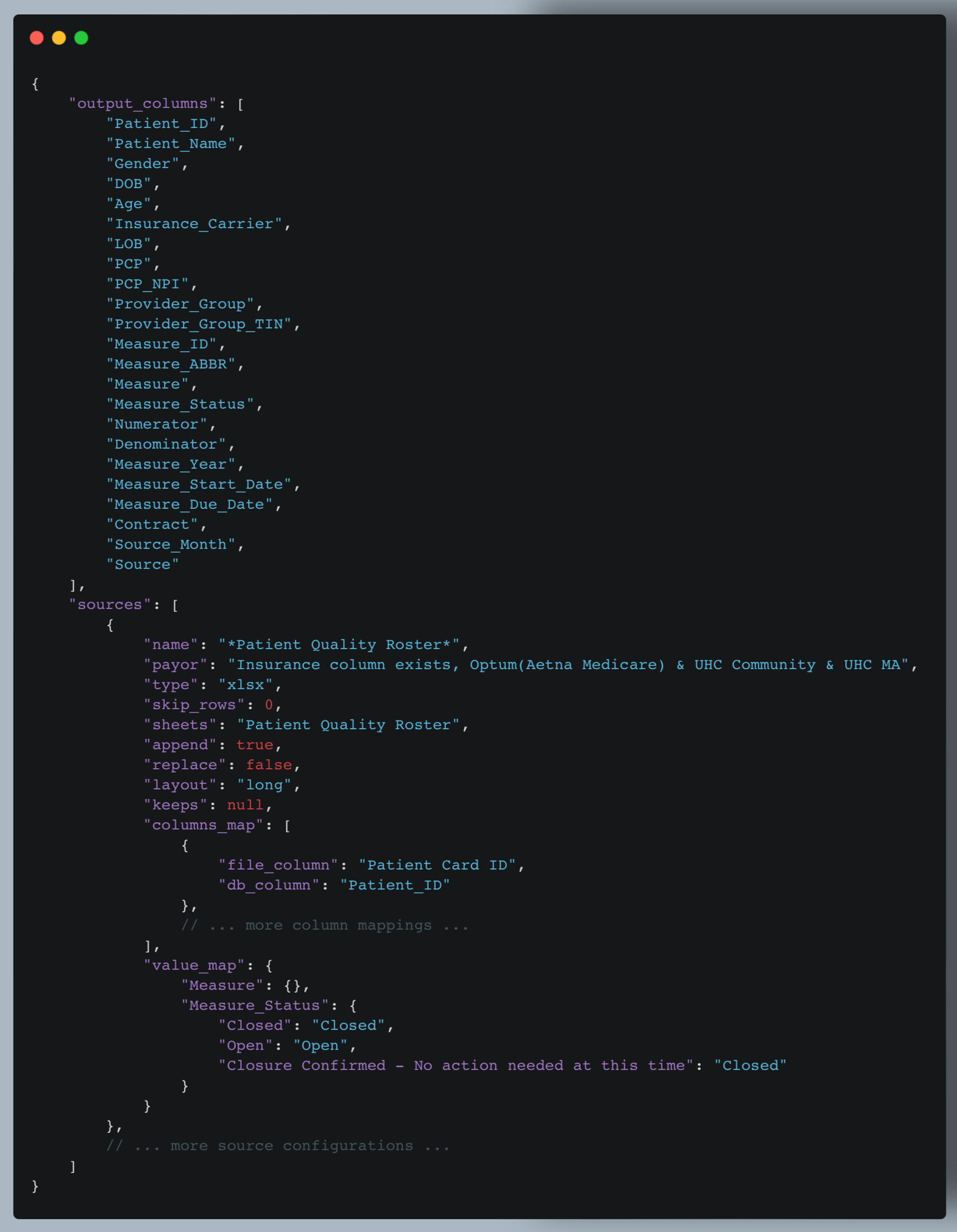
Key components of the configuration file:
- output_columns: Defines the standard set of columns that all transformed data should have. This ensures consistency across different source files.
- sources: An array of objects, each describing a specific source file type. Let's break down a source configuration:
- name: A pattern to match the file name. The use of wildcards (*) allows for flexible matching.
- payor: Identifies the insurance provider for this file type.
- type: Specifies the file type (e.g., xlsx, csv).
- skip_rows: Number of rows to skip when reading the file (useful for files with headers or metadata).
- sheets: For Excel files, specifies which sheet(s) to read.
- append/replace: Flags to determine how data should be added to existing datasets.
- layout: Indicates if the data is in "long" or "wide" format.
- keeps: Columns to retain during melt transformation (apply layout is wide).
- columns_map: Defines how source file columns map to standardized column names.
- value_map: Provides mappings for standardizing values in specific columns.
Example:
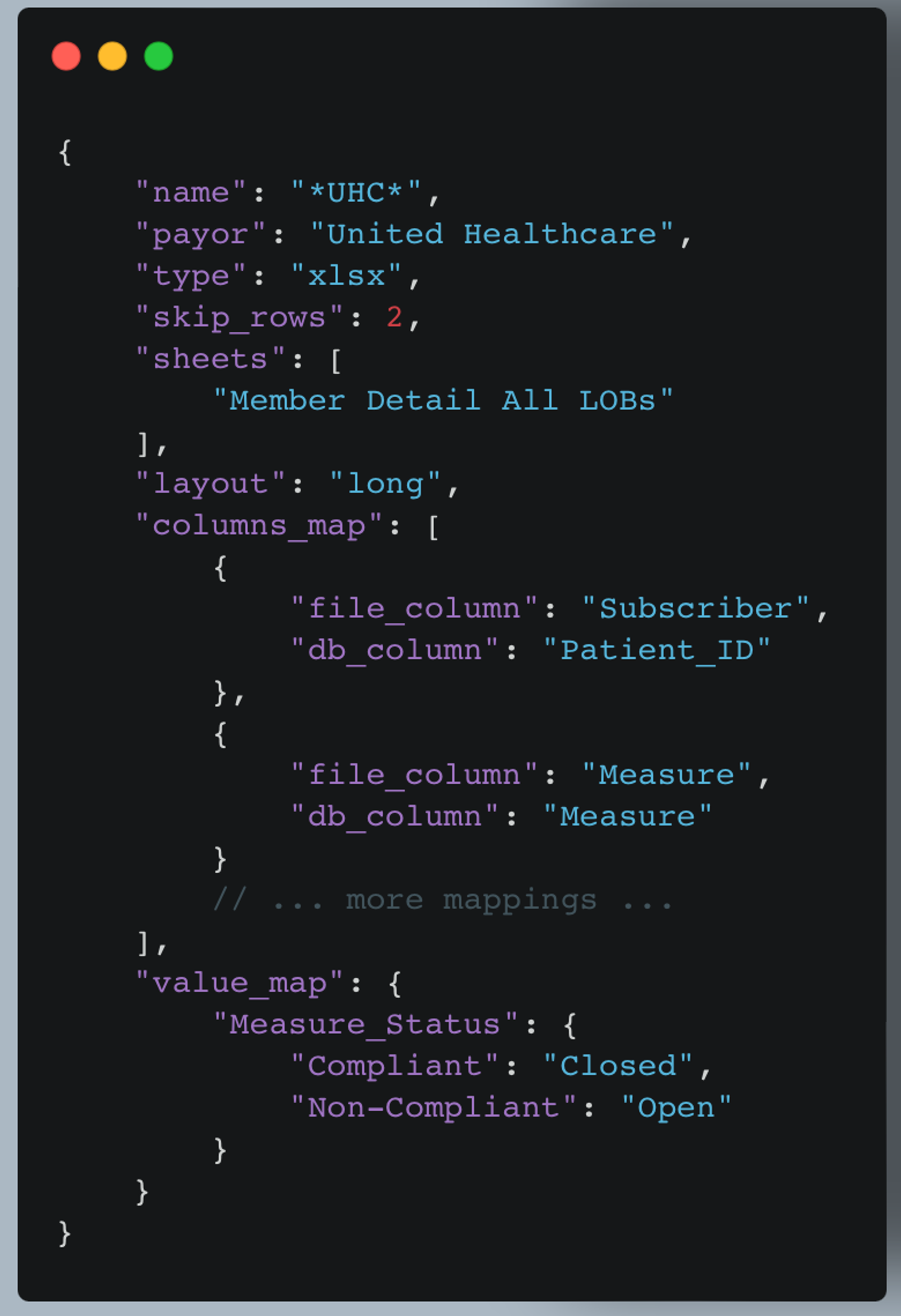
This configuration is for Excel files with "UHC" in the filename. It skips the first two rows, reads from a specific sheet, and includes both column mappings and value standardizations.
By using this flexible configuration structure, our ETL process can easily adapt to various file formats and naming conventions from different healthcare payers. The PayorDataExtractor and PayorDataTransformer classes use this configuration to determine how to read, interpret, and standardize the data from each source file.
This configuration-driven approach allows for easy addition of new data sources or modifications to existing ones without changing the core ETL code, making the system highly maintainable and extensible.
Benefits and Impact of the Project
Our healthcare data ETL solution offers numerous benefits and has a significant impact on healthcare data management and analysis:
- Improved Data Consistency: By standardizing data from various payers into a uniform format, we've significantly improved data consistency. This enables more accurate cross-payer comparisons and analyses, leading to better patient care and population health insights.
- Enhanced Efficiency: The automated ETL process dramatically reduces the time and effort required to process and standardize healthcare data. What once might have taken days or weeks of manual data wrangling can now be accomplished in hours, allowing healthcare professionals to focus more on analysis and less on data preparation.
- Reduced Errors: Automation and standardization significantly reduce the risk of human errors in data processing. This leads to more reliable data and, consequently, more trustworthy analytics and decision-making.
- Increased Scalability: Our solution can easily handle data from multiple payers and can be quickly adapted to new data sources. This scalability ensures that the system can grow with the organization's needs.
- Faster Insights: With data quickly standardized and readily available, healthcare organizations can generate insights and make data-driven decisions much faster.
- Better Patient Care: Ultimately, by providing a more comprehensive and accurate view of patient data across different payers, our solution contributes to better-informed clinical decisions and improved patient care.
The impact of this project extends beyond just data management. It empowers healthcare organizations to make more informed decisions, improve patient outcomes, and contribute to the overall advancement of data-driven healthcare practices.
Future Improvements or Extensions
While our current payor care gap data ETL solution provides significant value, there are several areas where we see potential for future improvements and extensions:
- Real-time Processing: Extend the system to support real-time or near-real-time data processing, allowing for more up-to-date analytics and faster response to changes in patient care needs.
- Advanced Data Quality Checks: Implement more sophisticated data quality checks, including statistical anomaly detection, to further improve data reliability.
- Interactive Configuration UI: Develop a user-friendly interface for managing configuration files, making it easier for non-technical users to adjust data source settings and mappings.
- Expanded Database Support: While our system is designed to be database-agnostic, we can create specific optimizations and connectors for other popular healthcare databases to improve performance and ease of use.
- API Integration: Develop APIs to allow other systems to easily trigger ETL processes or retrieve processed data, enhancing interoperability with other healthcare IT systems.
- Performance Optimization: Continually optimize the ETL processes for better performance, potentially incorporating distributed computing technologies for handling extremely large
These future improvements and extensions would further enhance the value of our ETL solution, keeping it at the forefront of healthcare data management technology. As the healthcare industry continues to evolve, our system will evolve with it, continually providing cutting-edge data processing capabilities to support better patient care and health outcomes.
Recommendations for Payers
Based on our experience working with various payer care gap files and HEDIS measures, we have the following recommendations for payers to improve their communication of care gaps:
- Standardize File Formats: Adopt a consistent file format across all care gap reports. Preferably use widely supported formats like CSV or Excel, with a clear, documented structure. This significantly reduces the complexity of data integration for providers and partners.
- Use Consistent Naming Conventions: Implement standardized naming conventions for measures, patient identifiers, and other key fields. This reduces the need for complex mapping in downstream processes and minimizes the risk of misinterpretation.
- Provide Comprehensive Metadata: Include a metadata sheet or section in each file that clearly defines all fields, measures, and any codes or abbreviations used. This improves understanding and reduces the need for clarifications.
- Adopt Industry Standard Measure IDs: Use widely recognized measure identifiers (e.g., HEDIS measure IDs) instead of proprietary codes. This facilitates easier cross-payer comparison and analysis and aligns with industry best practices.
- Offer Detailed and Summary Views: To meet user needs, provide detailed patient-level data and summary-level statistics. This allows for granular analysis and high-level reporting without additional data manipulation.
- Provide API Access: Consider offering API access to care gap data, allowing for more real-time and automated data retrieval by providers and partners.
By implementing these recommendations, payers can significantly improve the usability and value of their care gap reports, reducing the burden on providers and ultimately leading to better patient care and outcomes.
Conclusion
Developing this project to standardize and optimize the processing of patient care gap files has been a rewarding journey. By leveraging Python and a configuration file-driven approach, we created a flexible, database-agnostic solution that can handle various file formats and structures. This approach not only streamlined the ETL process but also ensured that the system could easily adapt to changes in data structures over time.
Throughout the project, we faced significant challenges, such as dealing with data quality issues and optimizing performance for large files. However, by implementing thoughtful solutions like standardized configuration files and batch processing, we overcame these obstacles and improved the overall efficiency and reliability of the ETL process.
This project underscores the importance of flexibility and adaptability in data processing solutions, particularly in healthcare industries where data can vary widely between sources. By open-sourcing this project, we hope to contribute to the broader community and provide a robust framework that others can build upon and adapt to their specific needs.