Enhancing Risk Scoring Accuracy for ACOs: A Comprehensive Series
Authors: Gilberto Izquierdo & Ashish Gupta
In the ever-evolving landscape of healthcare, a shift towards value-based care models has brought Accountable Care Organizations (ACOs) to the forefront of healthcare delivery and reimbursement reform. But what exactly are ACOs, and why are they important?
This blog post series will detail a project we undertook to enhance risk scoring accuracy by leveraging both Centers for Medicare & Medicaid Services (CMS) claims data and the organization's Electronic Health Record (EHR) system.
Understanding ACOs and the REACH Model
Accountable Care Organizations (ACOs) are groups of doctors, hospitals, and other healthcare providers who come together voluntarily to provide coordinated, high-quality care to their patients. The goal is simple yet ambitious: improve care quality while reducing unnecessary costs.
The ACO REACH Model, as described by CMS, is a redesigned version of the Global and Professional Direct Contracting (GPDC) Model. It focuses on three key areas:
- Promoting health equity and addressing healthcare disparities for underserved communities
- Continuing the momentum of provider-led organizations participating in risk-based models
- Protecting beneficiaries and the model with more participant vetting, monitoring, and oversight
The ACO REACH Model provides tools and resources to empower healthcare providers to better coordinate and improve the quality of care they provide for patients in Traditional Medicare. This approach offers patients greater individualized attention to their specific healthcare needs while preserving all services and flexibilities beneficiaries enjoy in Traditional Medicare.
The ultimate goal of ACO REACH is to provide beneficiaries with access to enhanced benefits and to increase the availability of high-quality, coordinated care, especially for people in underserved populations. It brings accountable care to Medicare beneficiaries who have previously lacked access in new and exciting ways.
The Importance of Risk Scoring in ACO REACH
Central to the success of ACOs participating in the REACH model is the concept of risk scoring. Risk scoring is a method used to assess the healthcare needs and potential costs of patient populations. It's based on various factors, including demographics, medical history, and socioeconomic indicators.
In the ACO REACH model, risk adjustment is used to adjust expenditures for beneficiary health risk and establish Performance Year Benchmarks. This ensures that payments are fair and accurate, reflecting the true health status of the population being served.
The CMMI Risk Adjustment Model
Unlike some other Medicare programs that use the Hierarchical Condition Category (HCC) model, the ACO REACH model employs a risk adjustment approach developed by the Center for Medicare and Medicaid Innovation (CMMI). This model includes:
- The CMS-HCC Prospective Risk Adjustment Model for beneficiaries aligned to Standard and New Entrant ACOs.
- A new CMMI-HCC Concurrent Risk Adjustment Model for beneficiaries aligned to High Needs Population ACOs.
The key difference in the CMMI-HCC concurrent model is its ability to capture rapid deterioration in health in the current year, making it particularly suitable for high-needs populations with complex, chronically sick, and seriously ill patients.
Purpose of This Blog Series
Our purpose in sharing this information is twofold:
- To provide insights and best practices for other care organizations facing similar challenges in implementing the ACO REACH model.
- To showcase how we're transforming our client companies through deeper technology initiatives, demonstrating the power of advanced data analytics in healthcare.
By sharing our experiences, challenges, and solutions, we hope to contribute to the broader healthcare technology community and inspire innovative approaches to healthcare data management and analysis.
Whether you're a healthcare professional, a data scientist, or simply someone interested in the intersection of healthcare and technology, we hope you'll find valuable insights in our journey to enhance risk scoring accuracy for ACO REACH.
Series Overview
This series will be divided into several parts, each focusing on a critical element of the project:
📘 Part 1: Processing ACO Reach Data from CMS in the Form of CCLF Files Diving into the intricacies of handling CMS claims data.
📘 Part 2: Integrating EHR Data Techniques for merging clinical documentation from eClinicalWorks.
📘 Part 3: Data Cleaning and Feature Engineering Strategies for ensuring data quality and creating meaningful features.
📘 Part 4: Implementing Risk Score Calculation Reimplementing CMMI's risk adjustment model using Python.
📘 Part 5: Visualization and Reporting Utilizing Power BI to create actionable dashboards.
The Challenge
ACO REACH participants face a complex task: Accurately predicting the healthcare needs and associated costs for their patient populations.
- Integrate data from multiple sources (CMS claims and EHR data, including patient notes, authorizations, and other unstructured sources)
- Identify gaps in documentation and coding
- Provide actionable insights for care management teams
- Improve the accuracy of financial benchmarks and projections
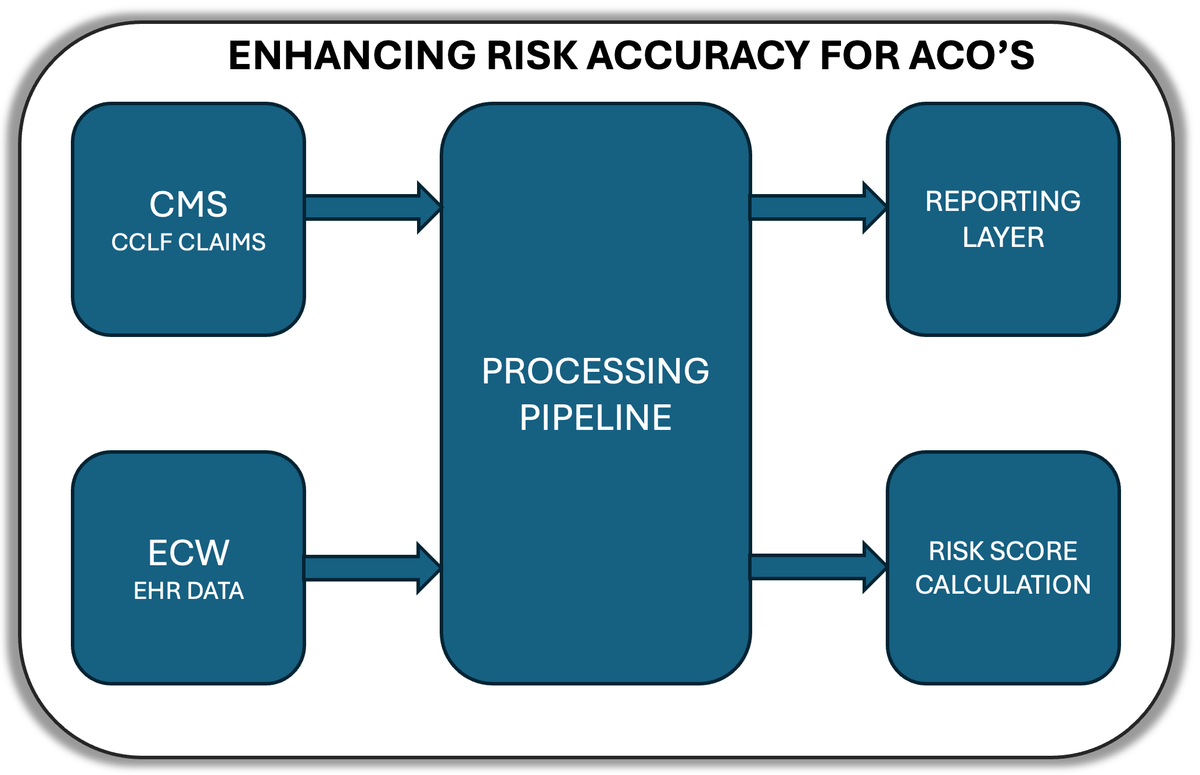
Data Sources and Technical Stack
Our project relied on two primary data sources:
- CCLF (Claim and Claim Line Feed) data from CMS: This includes detailed Medicare claims information for our attributed patients.
- eClinicalWorks EHR data: Organization's electronic health record system, containing clinical documentation, diagnoses, procedures, and other patient information.
To process, analyze, and visualize this data, we employed a robust technical stack:
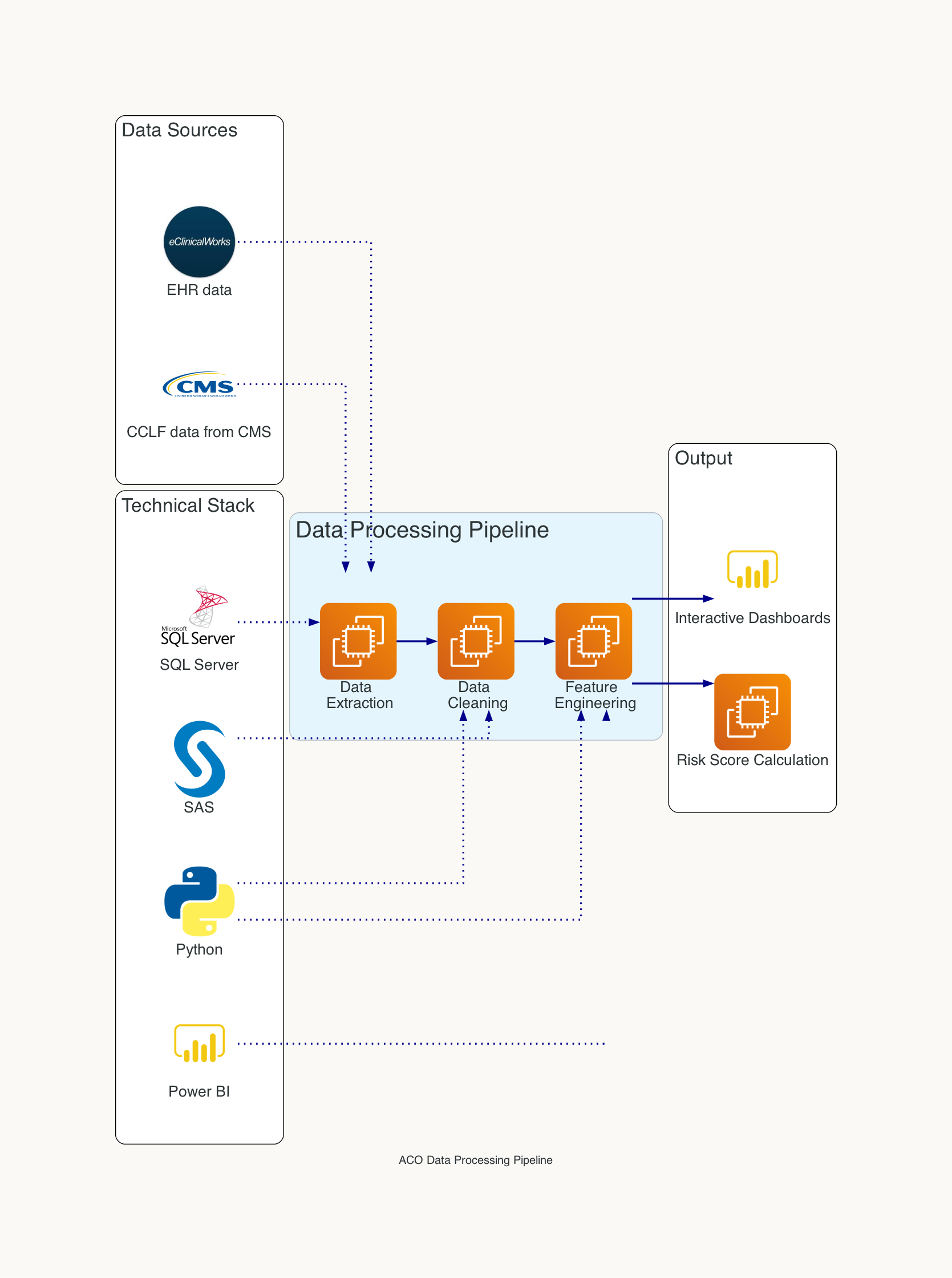
- SQL Server: For data storage and complex querying
- Python: Used for data preprocessing, feature engineering, and machine learning tasks
- SAS: Utilized for statistical analysis and model validation
- Power BI: Our tool of choice for creating interactive dashboards and reports
Data Processing and Integration
One of the most challenging aspects of this project was integrating the disparate data sources. Here's an overview of our data processing pipeline:
- Data Extraction: We developed scripts to extract relevant data from both the CCLF files and our eClinicalWorks EHR system.
- Data Cleaning: Using Python, we performed extensive data cleaning to handle missing values, standardize formats, and resolve inconsistencies between the two data sources.
- Feature Engineering: We created a set of features that capture various aspects of a patient's health status, utilization patterns, and demographic information.
Risk Score Calculation Methodology
A key technical challenge in our project was reimplementing the Center for Medicare and Medicaid Innovation (CMMI) risk adjustment model for High Needs Population in Python. Traditionally, these models are available through SAS and are provided by CMS, but we chose Python for its flexibility, extensive libraries, and integration capabilities with our existing data pipeline.
Visualization and Reporting
We leveraged Power BI to create a suite of interactive dashboards that provide actionable insights for our care management teams. These dashboards include:
- Population-level risk stratification
- Individual patient risk profiles
- Coding gap analysis
- Year-over-year risk score trends
Challenges and Solutions
Throughout this project, we encountered several challenges:
🚧 1. Data Quality Issues Inconsistencies between CCLF and EHR data required extensive validation and cleansing processes.
Solution: We implemented a series of data quality checks and reconciliation procedures to ensure data integrity.
🚧 2. Performance Optimization Processing large volumes of claims and EHR data presented performance challenges.
Solution: We optimized our SQL queries and implemented a distributed processing system using Python's multiprocessing library for computationally intensive tasks.
🚧 3. Model Interpretability Ensuring that our enhanced risk scoring model remained interpretable for clinical teams was crucial.
Solution: We developed a feature importance analysis tool that explains the factors contributing to each patient's risk score.
Future Improvements
As we look to the future, we've identified several areas for further enhancement:
- Incorporating natural language processing (NLP) techniques to extract additional risk factors from unstructured clinical notes
- Developing a machine learning model to predict future health events and refine risk scores
- Implementing a real-time risk scoring system that updates as new data becomes available
By continually refining our approach to risk scoring, we aim to improve patient outcomes, optimize resource allocation, and succeed in the ACO REACH model.
While we are focusing on the technical aspects of our risk scoring solution, it's important to consider its practical impact. How does this translate into real-world benefits?
- Improved Patient Outcomes: Early identification of high-risk patients enables timely interventions and personalized care plans.
- Efficient Resource Allocation: Better risk stratification allows healthcare organizations to focus resources where they're needed most, potentially reducing costs.
- Enhanced Provider Efficiency: Real-time risk scoring streamlines workflows and supports data-driven decision-making.
- Better Population Health Management: Aggregate risk data reveals population-level health trends, informing broader strategies.
- Increased Patient Engagement: Proactive, personalized care based on risk scores can lead to higher patient satisfaction and engagement.
Behind the scenes Part 1: Processing ACO Reach Data from CMS in the Form of CCLF Files
Stay tuned for the first part of our series where we will dive into the intricacies of transforming CCLF files from CMS. We'll explore the methods and tools used to extract, clean, and prepare this critical data source for accurate risk scoring.